

Все, традиционно привыкли что метаданные есть у фотографий, на крайний случай у видео. Но некоторые забывают, что метаданные есть и у других файлов, например у документов. И вот в этих метаданных часто есть имена учетных записей, электронные почты, иногда ФИО создателя документа, реже телефон. Это первая хорошая новость. Вторая, ещё более хорошая, о том что чистить метаданные документов редко кто заморачивается. Чисто теоретически, где-то могут добавить автоматическую очистку метаданных загружаемых документов, но, скажем так, это есть далеко не везде. И это прекрасно, с точки зрения OSINT. Особенно круто это работает с какими-нибудь государственными сайтами или крупными компаниями. Там где на сайты грузят просто нереальное количество всяких документов. Бывает качнешь так пару тысяч документов, и инфы получишь столько, как-будто пару лет в компании проработал. А ещё это абсолютно законно, я имею ввиду выкачка документов. Они ведь загружены чтобы их кто-то скачал, вот я и скачал. Просто сразу все.
Metagoofil и метаданные
В Kali Linux Metagoofil установить можно командой:
sudo apt install metagoofil
Для других дистрибутивов Metagoofil можно скачать здесь: https://github.com/opsdisk/metagoofil
Перед началом использования, вводи команду:
metagoofil -help
и смотрим доступные для использования параметры:
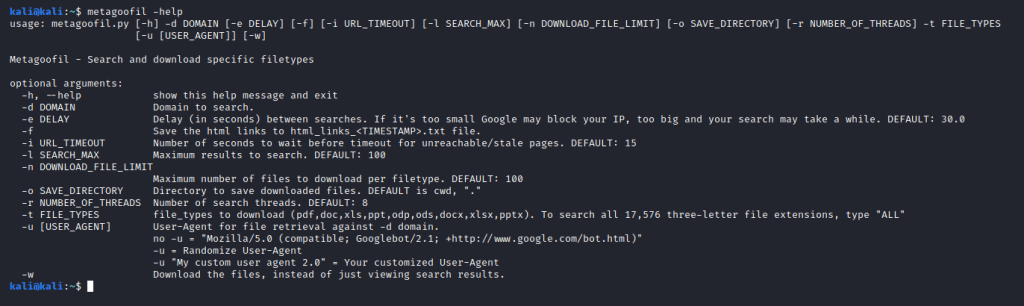
использование: metagoofil.py [-h] -d DOMAIN [-e DELAY] [-f] [-i URL_TIMEOUT] [-l SEARCH_MAX] [-n DOWNLOAD_FILE_LIMIT] [-o SAVE_DIRECTORY] [-r NUMBER_OF_THREADS] -t FILE_TYPES
[-u [USER_AGENT]] [-w]
Metagoofil - Search and download specific filetypes optional arguments:
-h, --help показать это справочное сообщение и выйти
-d DOMAIN Домен для поиска.
-e DELAY Задержка (в секундах) между поисками. Если она слишком мала, Google может заблокировать ваш IP-адрес, при слишком большой поиск может затянуться. ПО УМОЛЧАНИЮ: 30.0
-f Сохраните ссылки html в файл html_links_.txt.
-i URL_TIMEOUT Количество секунд ожидания до истечения времени ожидания для недоступных / устаревших страниц. ПО УМОЛЧАНИЮ: 15
-l SEARCH_MAX Максимум результатов для поиска. ПО УМОЛЧАНИЮ: 100
-n DOWNLOAD_FILE_LIMIT
Максимальное количество файлов для загрузки каждого типа файла. ПО УМОЛЧАНИЮ: 100
-o SAVE_DIRECTORY Каталог для сохранения загруженных файлов. ПО УМОЛЧАНИЮ - cwd, "."
-r NUMBER_OF_THREADS Количество поисковых потоков. ПО УМОЛЧАНИЮ: 8
-t FILE_TYPES типы файлов для загрузки (pdf,doc,xls,ppt,odp,ods,docx,xlsx,pptx). Чтобы найти все 17 576 трехбуквенных расширений файлов, введите «ALL».
-u [USER_AGENT] User-Agent для поиска файлов по домену -d.
если нет -u = "Mozilla/5.0 (compatible; Googlebot/2.1; http://www.google.com/bot.html)"
-u = Случайный выбор User-Agent
-u "My custom user agent 2.0" = Ваш индивидуальный User-Agent
-w Загрузить файлы, а не просто просматривать результаты поиска.
Теперь давай на примере посмотрим как это работает и какие результаты даёт. Как я уже говорил, админы государственных сайтов вообще не заморачиваются в своей работе, а потому, для наглядности, пробовать будем именно на примере госсайта. И в этой статье мой рандомный взгляд упал на сайт судебных приставов.
Для запуска используем такую команду:
metagoofil -d fssp.gov.ru -l 50 -n 50 -t pdf,doc,xls,docx,xlsx -o fssp
У нас получилась довольно типичная, для большинства случаев, команда. После параметра -d мы указали целевой домен. Затем установили лимит (-l) на результаты поиска в количестве 50, и столько же (-n) для скачивания найденных фалов. Потом добавили интересующие нас расширения файлов (-t), здесь стоит подбирать, в зависимости от специфики целевого сайта. Т.е. в моем примере очевидно, что наиболее актуальные, для подобного сайта, -щ это пдфки, документы и таблицы. И, в конце (-o), указываем папку куда будем сохранять файлы. Запускаем и ждем пока Metagoofil скачает найденные файлы.
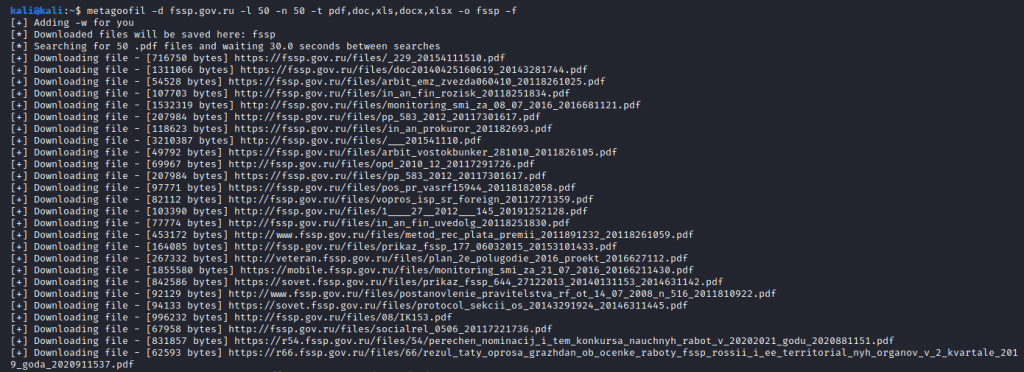
Очевидный совет, но все же. После скачивания, очень стоит ознакомится с документами. Там может попасться что-то такое, с чем интересно будет ознакомится.
Извлечение метаданных. Exiftool
Теперь давай извлечем метаданные, так сказать ручным способом. Для этого, как я и говорил, будем использовать exiftool. Для начала устанавливаем её:
sudo apt install exiftool
И запустим извлечение метаданных:
cd fssp
exiftool -r *.doc | egrep -i "Author|Creator|Email|Producer|Template" | sort -u
Мы перешли в каталог, куда выгружали документы, затем дали команду извлечь метаданные из всех документов с расширением doc, и затем отфильтровали результаты по нужным нам параметрам. Таким как автор документа, электронная почта и т.д.
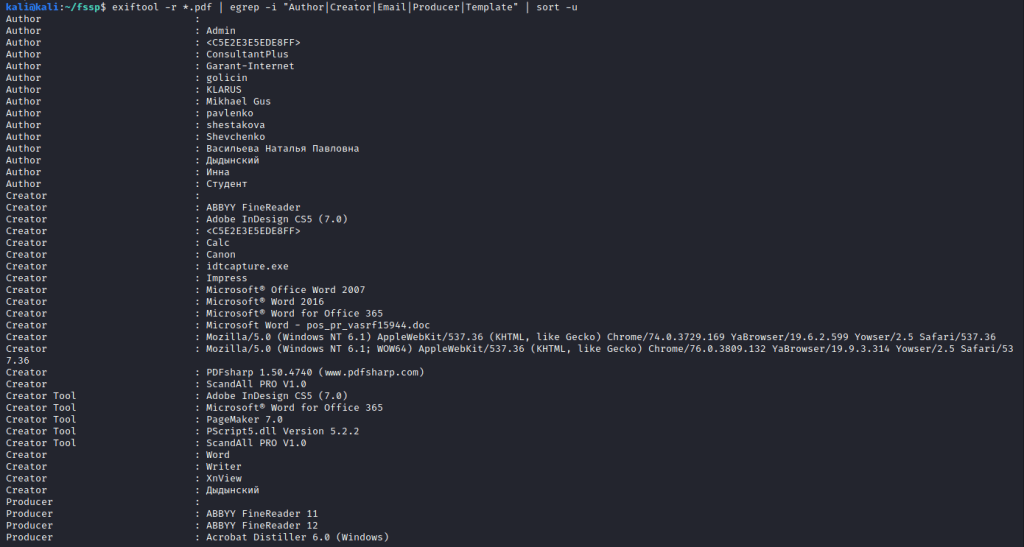
Тут нужно учитывать, что для каждого расширения файлов, извлекать метаданные придется отдельно.
Metagoofil 2.2
Теперь рассмотрим вторую версию Metagoofil. Я её рассматриваю исключительно из-за её наглядности. Потому что отчет который она формирует действительно не плох. Если бы не постоянные ошибки выкачки, блоки от гугла, была бы идеальная утилита.
Этой утилиты в репозиторияз Kali нет, потому качаем её с GitHub:
https://github.com/laramies/metagoofil
git clone https://github.com/laramies/metagoofil
cd metagoofil
Устанавливать ничего не нужно, автор уже добавил все необходимые зависимости. Сразу запускаем и смотрим доступные параметры для запуска:
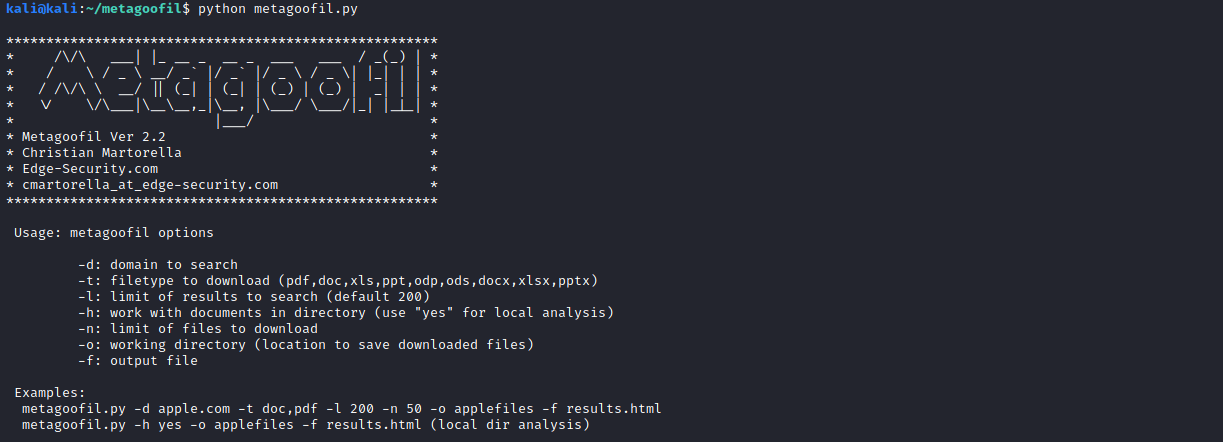
Usage: metagoofil options
-d: домен для поиска
-t: тип файла для загрузки (pdf,doc,xls,ppt,odp,ods,docx,xlsx,pptx)
-l: лимит результатов для поиска (default 200)
-h: работать с документами в каталоге (используйте «yes» для локального анализа)
-n: лимит файлов для скачивания
-o: рабочий каталог (место для сохранения загруженных файлов)
-f: выходной файл
Пример:
metagoofil.py -d apple.com -t doc,pdf -l 200 -n 50 -o applefiles -f results.html
metagoofil.py -h yes -o applefiles -f results.html (local dir analysis)
Возможно этой утилиты можно разделить на два направления: анализ метаданных уже скачанных файлов и скачивание файлов с целевого сайта и последующий анализ метаданных.
Анализ метаданных
Для начала посмотрим как проанализировать уже выкачанные файлы.
python metagoofil.py -h yes -o /home/kali/fssp -f result.html
Используя параметр -h мы даем команду работать локально, после чего (-o) указывает каталог где находятся файлы и (-f) название файла для отчета. К сожалению, срабатывает эта штука не всегда, потому если файл отчета не сгенерировался, нужно перезапустить утилиту.
Загрузка файлов и анализ метаданных
Второй вариант, это мы сначала скачиваем документы с целевого сайта, а потом утилита автоматически проанализирует их и выдаст файл с отчетом.
python metagoofil.py -d fsb.ru -t pdf,doc,docx,xls.xlsx -l 50 -n 50 -o fsspfiles -f fssp.html
Здесь по такому же принципу, как и в первый раз. Используя параметр -d мы указали целевой домен. После -t перечислили интересующие нас расширения файлов. Установили (-l) лимит на результаты поиска и лимит (-n) на скачивание. После параметра -o мы указали каталог куда скачивать документы и после -f указали как назвать файл с результатами. Каталог и файл с результатами будут находится в папке metagoofil.

Ждем какое-то время и приступаем к изучению результатов. А что изучать там будет всегда. Метаданные, причем любые, это ценнейший источник информации. На рассмотренных примерах, ты мог убедится что люди часто подписываются полными данными или используют свои никнеймы, под которыми наверняка регистрируются на других сайтах, тоже касается и электронных почт. Собрав всю эту информацию, ты получаешь кучу дополнительных направлений для поиска. По никнеймам можно поискать профили на форумах или социальных сетях. С электронными почтами та же история. Сведения о программном обеспечении, которое используется для создания документов, могут быть полезны с точки зрения пентеста. Так же совсем не лишней будет информация о месте хранения файлов на сервере. Как видишь, потратив совсем немного времени, мы получаем кучу полезной инфы.
Ну а если ты сам создаешь какие-то документы, или админишь какой-то ресурс, не ленись чистить метаданные, это не долго, а сбор инфы, для таких товарищей как я, немного усложнится. А потому не забывай про метаданные, они то про тебя никогда не забудут.
Metagoofil и метаданные
В Kali Linux Metagoofil установить можно командой:
sudo apt install metagoofil
Для других дистрибутивов Metagoofil можно скачать здесь: https://github.com/opsdisk/metagoofil
Перед началом использования, вводи команду:
metagoofil -help
и смотрим доступные для использования параметры:
использование: metagoofil.py [-h] -d DOMAIN [-e DELAY] [-f] [-i URL_TIMEOUT] [-l SEARCH_MAX] [-n DOWNLOAD_FILE_LIMIT] [-o SAVE_DIRECTORY] [-r NUMBER_OF_THREADS] -t FILE_TYPES
[-u [USER_AGENT]] [-w]
Metagoofil - Search and download specific filetypes optional arguments:
-h, --help показать это справочное сообщение и выйти
-d DOMAIN Домен для поиска.
-e DELAY Задержка (в секундах) между поисками. Если она слишком мала, Google может заблокировать ваш IP-адрес, при слишком большой поиск может затянуться. ПО УМОЛЧАНИЮ: 30.0
-f Сохраните ссылки html в файл html_links_.txt.
-i URL_TIMEOUT Количество секунд ожидания до истечения времени ожидания для недоступных / устаревших страниц. ПО УМОЛЧАНИЮ: 15
-l SEARCH_MAX Максимум результатов для поиска. ПО УМОЛЧАНИЮ: 100
-n DOWNLOAD_FILE_LIMIT
Максимальное количество файлов для загрузки каждого типа файла. ПО УМОЛЧАНИЮ: 100
-o SAVE_DIRECTORY Каталог для сохранения загруженных файлов. ПО УМОЛЧАНИЮ - cwd, "."
-r NUMBER_OF_THREADS Количество поисковых потоков. ПО УМОЛЧАНИЮ: 8
-t FILE_TYPES типы файлов для загрузки (pdf,doc,xls,ppt,odp,ods,docx,xlsx,pptx). Чтобы найти все 17 576 трехбуквенных расширений файлов, введите «ALL».
-u [USER_AGENT] User-Agent для поиска файлов по домену -d.
если нет -u = "Mozilla/5.0 (compatible; Googlebot/2.1; http://www.google.com/bot.html)"
-u = Случайный выбор User-Agent
-u "My custom user agent 2.0" = Ваш индивидуальный User-Agent
-w Загрузить файлы, а не просто просматривать результаты поиска.
Теперь давай на примере посмотрим как это работает и какие результаты даёт. Как я уже говорил, админы государственных сайтов вообще не заморачиваются в своей работе, а потому, для наглядности, пробовать будем именно на примере госсайта. И в этой статье мой рандомный взгляд упал на сайт судебных приставов.
Для запуска используем такую команду:
metagoofil -d fssp.gov.ru -l 50 -n 50 -t pdf,doc,xls,docx,xlsx -o fssp
У нас получилась довольно типичная, для большинства случаев, команда. После параметра -d мы указали целевой домен. Затем установили лимит (-l) на результаты поиска в количестве 50, и столько же (-n) для скачивания найденных фалов. Потом добавили интересующие нас расширения файлов (-t), здесь стоит подбирать, в зависимости от специфики целевого сайта. Т.е. в моем примере очевидно, что наиболее актуальные, для подобного сайта, -щ это пдфки, документы и таблицы. И, в конце (-o), указываем папку куда будем сохранять файлы. Запускаем и ждем пока Metagoofil скачает найденные файлы.
Очевидный совет, но все же. После скачивания, очень стоит ознакомится с документами. Там может попасться что-то такое, с чем интересно будет ознакомится.
Извлечение метаданных. Exiftool
Теперь давай извлечем метаданные, так сказать ручным способом. Для этого, как я и говорил, будем использовать exiftool. Для начала устанавливаем её:
sudo apt install exiftool
И запустим извлечение метаданных:
cd fssp
exiftool -r *.doc | egrep -i "Author|Creator|Email|Producer|Template" | sort -u
Мы перешли в каталог, куда выгружали документы, затем дали команду извлечь метаданные из всех документов с расширением doc, и затем отфильтровали результаты по нужным нам параметрам. Таким как автор документа, электронная почта и т.д.
Тут нужно учитывать, что для каждого расширения файлов, извлекать метаданные придется отдельно.
Metagoofil 2.2
Теперь рассмотрим вторую версию Metagoofil. Я её рассматриваю исключительно из-за её наглядности. Потому что отчет который она формирует действительно не плох. Если бы не постоянные ошибки выкачки, блоки от гугла, была бы идеальная утилита.
Этой утилиты в репозиторияз Kali нет, потому качаем её с GitHub:
https://github.com/laramies/metagoofil
git clone https://github.com/laramies/metagoofil
cd metagoofil
Устанавливать ничего не нужно, автор уже добавил все необходимые зависимости. Сразу запускаем и смотрим доступные параметры для запуска:
Usage: metagoofil options
-d: домен для поиска
-t: тип файла для загрузки (pdf,doc,xls,ppt,odp,ods,docx,xlsx,pptx)
-l: лимит результатов для поиска (default 200)
-h: работать с документами в каталоге (используйте «yes» для локального анализа)
-n: лимит файлов для скачивания
-o: рабочий каталог (место для сохранения загруженных файлов)
-f: выходной файл
Пример:
metagoofil.py -d apple.com -t doc,pdf -l 200 -n 50 -o applefiles -f results.html
metagoofil.py -h yes -o applefiles -f results.html (local dir analysis)
Возможно этой утилиты можно разделить на два направления: анализ метаданных уже скачанных файлов и скачивание файлов с целевого сайта и последующий анализ метаданных.
Анализ метаданных
Для начала посмотрим как проанализировать уже выкачанные файлы.
python metagoofil.py -h yes -o /home/kali/fssp -f result.html
Используя параметр -h мы даем команду работать локально, после чего (-o) указывает каталог где находятся файлы и (-f) название файла для отчета. К сожалению, срабатывает эта штука не всегда, потому если файл отчета не сгенерировался, нужно перезапустить утилиту.
Загрузка файлов и анализ метаданных
Второй вариант, это мы сначала скачиваем документы с целевого сайта, а потом утилита автоматически проанализирует их и выдаст файл с отчетом.
python metagoofil.py -d fsb.ru -t pdf,doc,docx,xls.xlsx -l 50 -n 50 -o fsspfiles -f fssp.html
Здесь по такому же принципу, как и в первый раз. Используя параметр -d мы указали целевой домен. После -t перечислили интересующие нас расширения файлов. Установили (-l) лимит на результаты поиска и лимит (-n) на скачивание. После параметра -o мы указали каталог куда скачивать документы и после -f указали как назвать файл с результатами. Каталог и файл с результатами будут находится в папке metagoofil.
Ждем какое-то время и приступаем к изучению результатов. А что изучать там будет всегда. Метаданные, причем любые, это ценнейший источник информации. На рассмотренных примерах, ты мог убедится что люди часто подписываются полными данными или используют свои никнеймы, под которыми наверняка регистрируются на других сайтах, тоже касается и электронных почт. Собрав всю эту информацию, ты получаешь кучу дополнительных направлений для поиска. По никнеймам можно поискать профили на форумах или социальных сетях. С электронными почтами та же история. Сведения о программном обеспечении, которое используется для создания документов, могут быть полезны с точки зрения пентеста. Так же совсем не лишней будет информация о месте хранения файлов на сервере. Как видишь, потратив совсем немного времени, мы получаем кучу полезной инфы.
Ну а если ты сам создаешь какие-то документы, или админишь какой-то ресурс, не ленись чистить метаданные, это не долго, а сбор инфы, для таких товарищей как я, немного усложнится. А потому не забывай про метаданные, они то про тебя никогда не забудут.