Всех с праздником)
Большинство разработчиков ПО изпользуют систему контроля версий, такую как Git, для отслеживания изменений в исходном коде проекта во время разработки программного обеспечения. Когда инженер-программист использует Git, он обычно включает каталог git, расположенный в корне веб-сайта, для хранения всей информации о контроле версий проекта, включая историю коммитов некоторых файлов. Папка /.git/ должна иметь ограничения на чтение, иначе исходный код проекта может быть скомпрометирован. Те кто решал web-таски на таких платформах как rootme.org или tryhackme должны быть знакомы с подобным видом уязвимостей.
Чем мы сегодня будем заниматься?
1. Поиск уязвимых веб-приложений при помощи Google-dorks и поисковой системы Shodan.
2. Выкачивание каталогов из .git + ревью софта.
3. Exctract-им коммиты репозитория и получаем исходный код.
Вообще, помимо Git существует множество других систем контроля версий, таких как CVS (система параллельных версий), SVN (подрывная версия Apache), BZR (Bazaar) и HG (Mercurial). Сегодня мы рассмотрим конкретно систему контроля версий Git, так как она является самой распространенной.
I. Ищем уязвимые веб-приложения.
1. Поисковая система Google и поиск по Google-dorks.
Выполнив поиск по Google-dork: intitle: "Index of /.git" , мы получаем веб сайты с общедоступными .git репозиториями открытыми в режиме чтения.

2. Поисковая система Shodan.
Shodan — это поисковая система для всего, что есть в Интернете. Используя запрос http.title:"Index of /" http.html:".git", он вернет вам список веб-сайтов с открытым репозиторием .git.

II. Выкачиваем каталог /.git/ и изучаем софт.
Итак, мы определили для себя цель и готовы выкачивать исходный код сайта. Я выбрал https://schweizerrsg.com - производитель вертолетной техники в пендосии.
Их сайт основан на свободной и бесплатной CMS WordPress, так что вреда мы им практически не принесем (что и к лучшему).

Как мы видим, здесь у нас открыт /.git/ для чтения.

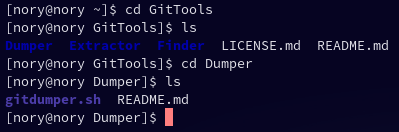
На данном этапе нам потребуется утилита "GitTools" - https://github.com/internetwache/GitTools .
Клонируем репозиторий через git clone. Теперь нам нужен раздел "Dumper". При помощи него мы будет клонировать все файлы из /.git/ на наше устройство.

Сперва указываем сайт на котором находится каталог /.git/ потом место куда мы хотим его скопировать.
Итак, у нас пошел процесс выкачивания.

III. Извелкаем исходники сайта.
После всего этого мы получаем 1 в 1 клонированный /.git/ на своем устройстве. Но мы не видим того самого исходного кода. Что делать? А теперь нам нужно все это дело распаковать. Для этого в GitTools переходим в Extractor и запускаем его. Слева - папка с клонированным /.git/, справа - куда нужно вытаскивать исходники.

Итак, мы извлекли данные из /.git/ и сейчас мы посмотрим что получилось.
Как мы видим, в /.git/ у них хранились 2 версии проекта.

Идем далее.

Так как сайт у них основывается на СMS WordPress, можем видеть полную структуру сайта с плагинами и папками. Пример не самый лучший но, при помощи него можно спокойно поставить фишинговый сайт, ведь все плагины уже заранее настроены и вся струкутура сохранена. На свой движок они поставили большое множество плагинов для защиты и безопасности. Но всего одна маленькая ошибка конфигурации...
На данном примере мы разобрали сайт на CMS WordPress и, надеюсь, принесли ему минимальное количество вреда. А если сайт самописный или на другом CMS? Здесь уже может быть все гораздо серьезней. Взглянем на пример в виде https://www.dataone.io/ . Сдампив его каталог /.git/ я получил 13 версий проекта по которым можно отследить его развитие, весь backend рукописный (с комментариями, будет что почитать) а также дамп базы данных phpMyAdmin.

Cкажите, уже посерьезней?
Бывает и такое что папка /.git/ может не показываться на сайте. В этом случае все-равно нужно проверять GitTools на наличие данных в /.git/ . Наглядный пример: polsa.gov.pl .
Итак, сегодня мы разобрались как обнаруживать, выкачивать и извлекать данные из каталогов /.git/ сайтов. А также на нескольких наглядных примерах поняли, почему оставлять папку /.git/ в корне сайта доступной для чтения - плохая идея.
Надеюсь что вам понравился гайд. В первую очередь он направляется "Zаря" и "XakNet". Парни, разьебите всех)
Большинство разработчиков ПО изпользуют систему контроля версий, такую как Git, для отслеживания изменений в исходном коде проекта во время разработки программного обеспечения. Когда инженер-программист использует Git, он обычно включает каталог git, расположенный в корне веб-сайта, для хранения всей информации о контроле версий проекта, включая историю коммитов некоторых файлов. Папка /.git/ должна иметь ограничения на чтение, иначе исходный код проекта может быть скомпрометирован. Те кто решал web-таски на таких платформах как rootme.org или tryhackme должны быть знакомы с подобным видом уязвимостей.
Чем мы сегодня будем заниматься?
1. Поиск уязвимых веб-приложений при помощи Google-dorks и поисковой системы Shodan.
2. Выкачивание каталогов из .git + ревью софта.
3. Exctract-им коммиты репозитория и получаем исходный код.
Вообще, помимо Git существует множество других систем контроля версий, таких как CVS (система параллельных версий), SVN (подрывная версия Apache), BZR (Bazaar) и HG (Mercurial). Сегодня мы рассмотрим конкретно систему контроля версий Git, так как она является самой распространенной.
I. Ищем уязвимые веб-приложения.
1. Поисковая система Google и поиск по Google-dorks.
Выполнив поиск по Google-dork: intitle: "Index of /.git" , мы получаем веб сайты с общедоступными .git репозиториями открытыми в режиме чтения.
2. Поисковая система Shodan.
Shodan — это поисковая система для всего, что есть в Интернете. Используя запрос http.title:"Index of /" http.html:".git", он вернет вам список веб-сайтов с открытым репозиторием .git.
II. Выкачиваем каталог /.git/ и изучаем софт.
Итак, мы определили для себя цель и готовы выкачивать исходный код сайта. Я выбрал https://schweizerrsg.com - производитель вертолетной техники в пендосии.
Их сайт основан на свободной и бесплатной CMS WordPress, так что вреда мы им практически не принесем (что и к лучшему).
Как мы видим, здесь у нас открыт /.git/ для чтения.
На данном этапе нам потребуется утилита "GitTools" - https://github.com/internetwache/GitTools .
Клонируем репозиторий через git clone. Теперь нам нужен раздел "Dumper". При помощи него мы будет клонировать все файлы из /.git/ на наше устройство.
Сперва указываем сайт на котором находится каталог /.git/ потом место куда мы хотим его скопировать.
Итак, у нас пошел процесс выкачивания.
III. Извелкаем исходники сайта.
После всего этого мы получаем 1 в 1 клонированный /.git/ на своем устройстве. Но мы не видим того самого исходного кода. Что делать? А теперь нам нужно все это дело распаковать. Для этого в GitTools переходим в Extractor и запускаем его. Слева - папка с клонированным /.git/, справа - куда нужно вытаскивать исходники.
Итак, мы извлекли данные из /.git/ и сейчас мы посмотрим что получилось.
Как мы видим, в /.git/ у них хранились 2 версии проекта.
Идем далее.
Так как сайт у них основывается на СMS WordPress, можем видеть полную структуру сайта с плагинами и папками. Пример не самый лучший но, при помощи него можно спокойно поставить фишинговый сайт, ведь все плагины уже заранее настроены и вся струкутура сохранена. На свой движок они поставили большое множество плагинов для защиты и безопасности. Но всего одна маленькая ошибка конфигурации...
На данном примере мы разобрали сайт на CMS WordPress и, надеюсь, принесли ему минимальное количество вреда. А если сайт самописный или на другом CMS? Здесь уже может быть все гораздо серьезней. Взглянем на пример в виде https://www.dataone.io/ . Сдампив его каталог /.git/ я получил 13 версий проекта по которым можно отследить его развитие, весь backend рукописный (с комментариями, будет что почитать) а также дамп базы данных phpMyAdmin.
Cкажите, уже посерьезней?
Бывает и такое что папка /.git/ может не показываться на сайте. В этом случае все-равно нужно проверять GitTools на наличие данных в /.git/ . Наглядный пример: polsa.gov.pl .
Итак, сегодня мы разобрались как обнаруживать, выкачивать и извлекать данные из каталогов /.git/ сайтов. А также на нескольких наглядных примерах поняли, почему оставлять папку /.git/ в корне сайта доступной для чтения - плохая идея.
Надеюсь что вам понравился гайд. В первую очередь он направляется "Zаря" и "XakNet". Парни, разьебите всех)